서강대학교 수학과 김종락 교수팀(CICAGO Lab)과 딥파운틴이 공동으로 수행한 '한국 국가대표 AI 수학 문제 해결 능력 평가' 결과가 발표되었습니다. 이번 평가는 자체 구축한 수학 추론 리더보드 'EntropyMath'를 활용하여 국내 주요 국가대표 AI 모델의 '실제 지능'을 가늠하는 새로운 시험대로서 큰 주목을 받았습니다.

그림 1. 자체 제작 데이터셋(Seed-10)에 대한 5대 국가대표 AI와 국외 모델의 성능 비교
평가 개요: 언어 유창성을 넘어 '순수한 추론'으로
기존 글로벌 벤치마크들은 영어권 문화와 서사에 편향되어 있어 한국어 기반 모델의 진정한 실력을 평가하기 어려웠습니다. 이에 연구진은 한국 연구진이 직접 검증한 140개 이상의 고난도 수학 문제로 구성된 EntropyMath를 개발했습니다. 이는 단순한 정답 맞추기가 아닌, AI가 실제로 '생각'하고 '추론'하는 능력을 공정하게 측정하기 위해 설계되었습니다.
주요 평가 결과: Solar-Pro-2의 약진
평가 결과, 국내 모델 중에서는 업스테이지의 'Solar-Pro-2'가 가장 인상적인 성과를 보였습니다. 31B 규모의 중형 모델임에도 불구하고 정확도 53.3%, Pass@3 기준 70.0%를 기록하며 대형 모델에 버금가는 사고 능력을 입증했습니다.
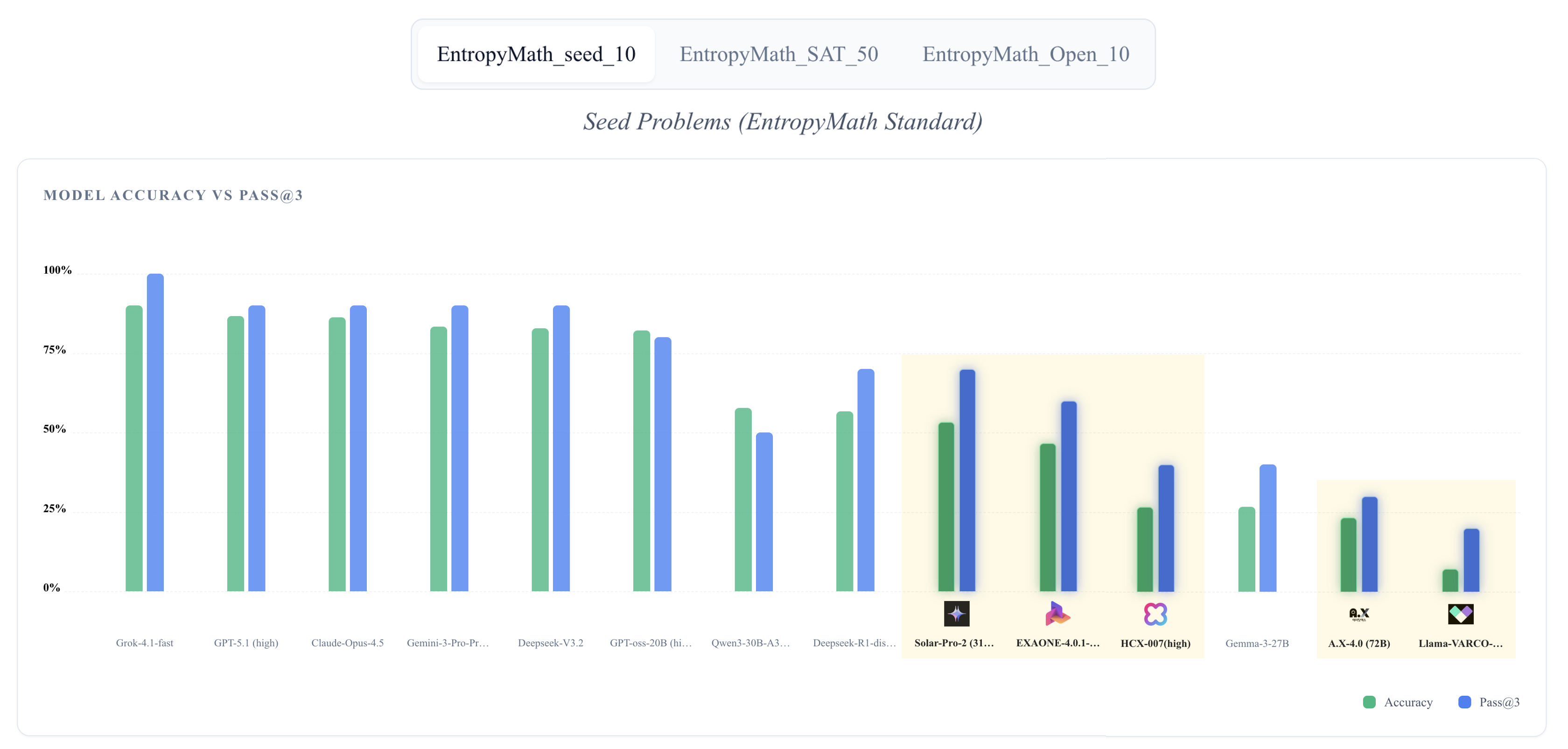
그림 2. 국내 주요 국가대표 AI 모델들의 성능 비교표
Solar-Pro-2 (1위)
정확도 53.3%. 복잡한 수학 문제에서도 일관된 정답률을 보이며, 국내 모델 중 유일하게 과반 이상의 정답률을 기록했습니다.
EXAONE 4.0.1 (2위)
정확도 46.7%. 다국어 처리 능력과 고난도 문제 해결력의 균형이 돋보이며 안정적인 2위를 기록했습니다.
반면 SK텔레콤의 'A.X 4.0(72B)'은 큰 모델 크기에도 불구하고 낮은 정답률을 보여 "파라미터 수가 곧 추론 능력을 보장하지 않는다"는 시사점을 남겼습니다.
Seed-10: 변별력의 핵심
기존 수능(CSAT) 문제에서는 상위권 모델 간의 격차가 크지 않았으나, 연구진이 별도로 제작한 'Seed-10' 고난도 문제 세트에서는 성능 차이가 극명하게 드러났습니다. 이 문제들은 단순 계산이나 패턴 매칭으로는 풀 수 없으며, AI가 파이썬(Python) 도구를 활용해 계산하고 그 결과를 다시 논리적으로 해석해야만 정답에 도달할 수 있는 '에이전틱(Agentic)' 능력을 요구합니다.

그림 3. 에이전틱 추론 능력을 요구하는 EntropyMath Seed-10 Hard 문제 예시
EntropyMath: 지속 가능한 벤치마크
EntropyMath는 일회성 평가에 그치지 않고, 자동 문제 생성 알고리즘을 통해 지속 가능한 평가 생태계를 구축합니다. 초기 Seed 문제들을 분해(decompose)하고 재조합(mix)하여 구조적 난이도가 제어된 새로운 문제들을 끊임없이 생성함으로써, 평가 데이터가 모델 학습 데이터에 오염(contamination)되는 것을 방지합니다.
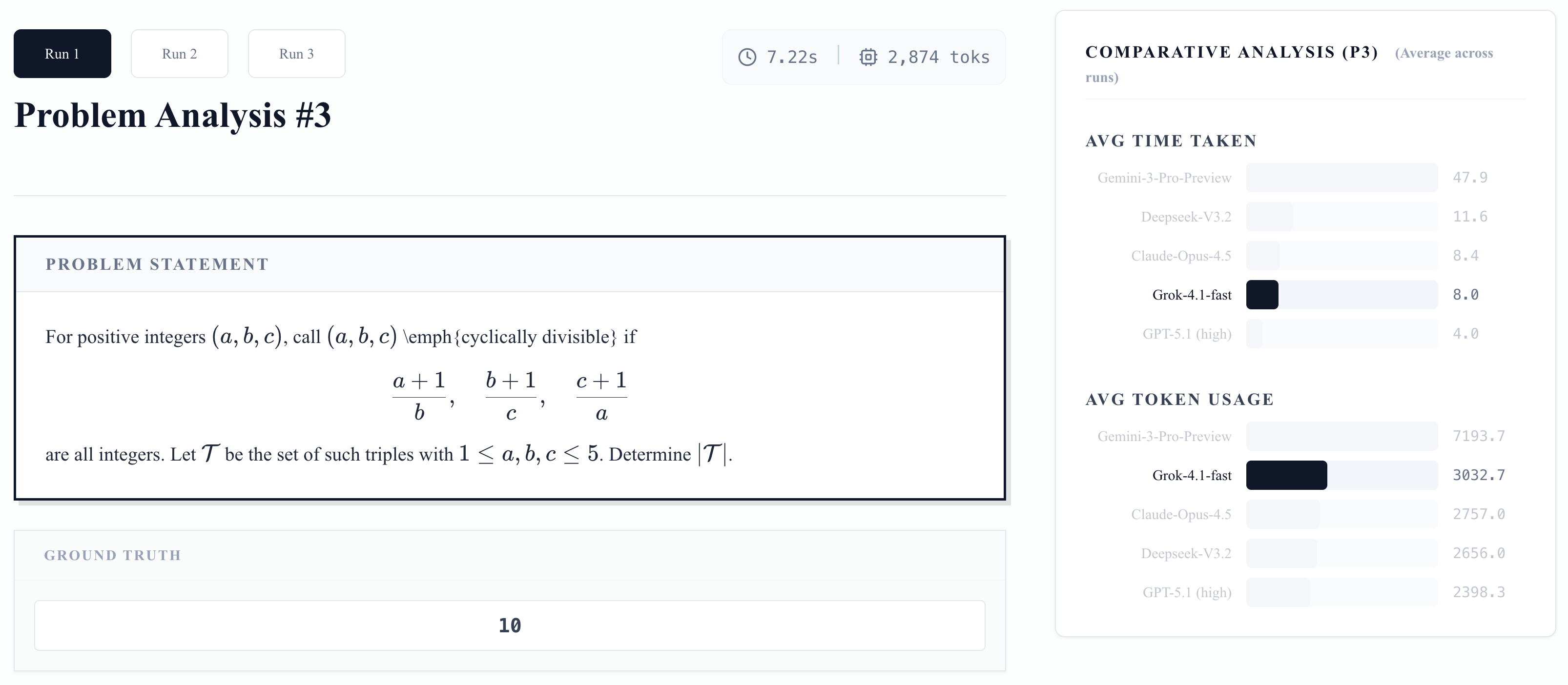
그림 4. 자체 알고리즘으로 생성된 EntropyMath 파생 문제 예시
"이번 연구결과는 한국 AI가 글로벌 빅테크의 '패스트 팔로워(Fast Follower)'를 넘어, 수학적 추론이라는 가장 엄밀한 기준에서 대등한 경쟁력을 갖춘 '퍼스트 무버(First Mover)'로 도약할 기반을 마련했음을 보여줍니다." - 서강대 김종락 교수 (딥파운틴 대표)